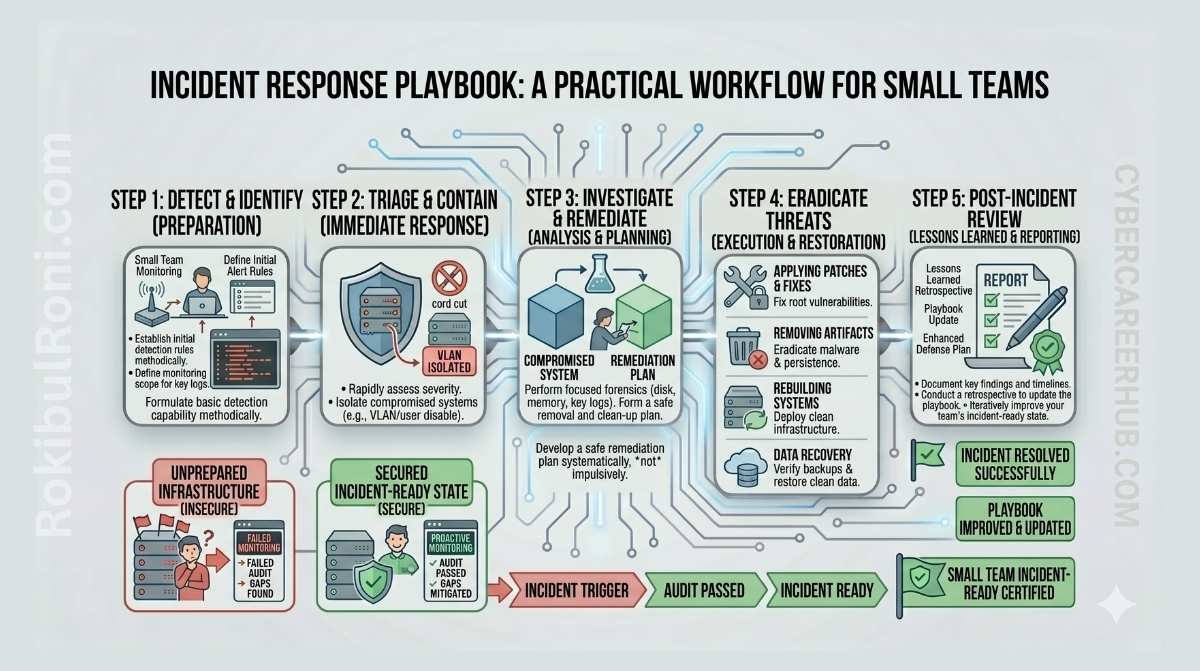
Small teams don’t fail incident response because they lack enterprise tooling. They fail because nobody agreed beforehand on who’s in charge, communication stalls when pressure spikes, and evidence gets destroyed in the rush to clean things up.
A written playbook fixes that. It turns a chaotic first hour into a sequence: who leads, what gets isolated, what gets preserved, who gets called, and how you confirm recovery actually worked before declaring the incident closed.
You don’t need a 200-page program. You need something short enough that people will actually read it and practiced enough that they can execute it under stress.
Incident Response Playbook for Small Teams
Use this as a minimum viable response system for lean IT and security teams.
1) Why Small Teams Need a Written IR Playbook
When an incident hits, ad-hoc decision-making is unreliable. Incidents move faster than you expect, people second-guess themselves without a defined authority structure, and important steps get skipped because everyone assumes someone else handled them.
The problems compound quickly:
- Role confusion in the first hour delays containment, which extends the attacker’s window
- Without predefined communication paths, the wrong people get called too late or not at all
- Evidence overwritten during rushed cleanup can make root cause analysis impossible later
- Unclear decision authority leads to paralysis or contradictory actions at the worst possible time
A short, usable playbook beats a perfect document that lives in a SharePoint folder no one can find under pressure.
2) Minimum Viable Incident Response Plan
If your team is resource-constrained, focus on the elements that directly affect containment speed and recovery quality. Everything else can be refined over time.
Core Plan Components
- Clear definition of what counts as an incident and what triggers escalation
- Severity classification with explicit thresholds and response times
- Named role assignments with backups for each position
- A contact matrix covering internal and external parties
- A defined evidence handling and storage process
- A containment decision flow so no one freezes at a critical moment
- A recovery validation checklist before declaring systems clean
- Post-incident review requirements so lessons actually get captured
Minimum Viable IR Artifacts
| Artifact | Purpose | Owner |
|---|---|---|
| One-page response flow | Rapid action sequence under pressure | Incident lead |
| Severity matrix | Consistent triage and escalation decisions | Security or IT owner |
| Contact matrix | Fast communication routing during the first hour | Operations manager |
| Evidence log template | Chain-of-custody and artifact traceability | Technical responder |
| Executive update template | Consistent leadership communication without information overload | Incident lead |
3) Roles and Responsibilities for Lean Teams
Small organizations often can’t staff a dedicated role for every function. That’s fine — assign the roles anyway and map one person to multiple responsibilities where necessary. The important thing is that every role has a named owner before an incident starts, not during one.
| Role | Primary Responsibility | Backup Responsibility |
|---|---|---|
| Incident Lead | Owns the timeline, decisions, and cross-functional coordination | Provides executive updates when comms owner is unavailable |
| IT Owner | Infrastructure containment and recovery execution | Supports evidence collection logistics |
| Executive Contact | Business decision authority and operational prioritization | Approves risk tradeoffs during high-severity events |
| Legal/Privacy Contact | Regulatory obligations and disclosure guidance | Reviews all external communications before they go out |
| Communications Owner | Internal and external messaging consistency | Manages customer and stakeholder update cadence |
| Vendor Contact | Third-party support escalation (cloud provider, ISP, MSSP) | Relays technical incident context to vendors |
RACI-Style Action Map
| Action | Incident Lead | IT Owner | Executive | Legal/Privacy | Communications | Vendor Contact |
|---|---|---|---|---|---|---|
| Severity declaration | A | C | I | I | I | I |
| Host isolation decision | A | R | C | I | I | C |
| Evidence preservation | C | R | I | C | I | I |
| Breach disclosure decision | C | I | A | R | R | I |
| Recovery go-live approval | C | R | A | C | I | C |
R = Responsible, A = Accountable, C = Consulted, I = Informed
4) Preparation Checklist Before Any Incident Happens
The best time to prepare for an incident is well before you’re having one. Most response failures trace back to preparation failures — missing logs, untested backups, outdated contact information. These are all fixable before the pressure is on.
Readiness Checklist
- Current asset inventory covering servers, endpoints, SaaS applications, and cloud workloads
- Backup coverage validated with documented restore test records
- MFA enabled for all privileged and remote access accounts
- Logging enabled on critical systems, identity providers, and network edges
- Endpoint protection deployed and reporting to a central management console
- Password reset and forced credential rotation process documented and tested
- Vendor escalation contacts validated on a quarterly basis
- Cyber insurance contacts and policy constraints documented, including any incident notification requirements
- Secure evidence storage location defined with access controls in place
Preparation Reference Table
| Control Area | Minimum Standard | Validation Method |
|---|---|---|
| Asset Inventory | Critical assets and owners documented | Monthly ownership review |
| Backups | Daily backups with periodic restore tests | Restore drill evidence on file |
| Identity Security | MFA enforced on admin and high-risk accounts | IAM policy audit |
| Logging | Auth, endpoint, firewall, and cloud audit logs retained with defined retention period | SIEM or log platform check |
| Endpoint Protection | Coverage verified across all production endpoints | Agent inventory report |
| Evidence Storage | Encrypted, access-controlled repository tested for write and retrieval | Access review and test upload |
5) Incident Phases With Practical Actions
This sequence gives your team operational consistency across different incident types. The phases aren’t rigid — you may run containment and evidence preservation in parallel in fast-moving situations — but the overall flow should hold.
Phase 1: Prepare
Confirm playbook owners and on-call structure before any incident occurs. Validate logging health and alerting pathways regularly. Run tabletop exercises for your highest-probability scenarios at least quarterly.
Phase 2: Identify
Gather alert context and determine the affected scope. Assign a severity level using your predefined matrix. Open a formal incident record with a timestamped timeline from the start.
Phase 3: Contain
Isolate affected hosts, accounts, or services based on spread risk and business impact. Focus first on stopping lateral movement while keeping critical business services running where safe to do so. Document every containment action with a timestamp — you’ll need this for the post-incident review.
Phase 4: Preserve Evidence
Capture volatile data (RAM, active network connections, running processes) before powering down or wiping anything. Work from copies for analysis and protect originals. Record chain-of-custody for every artifact you collect.
Phase 5: Eradicate
Remove malicious artifacts, unauthorized persistence mechanisms, and any backdoors identified during analysis. Patch the exploited weakness and rotate all credentials that may have been exposed. Validate cleanup through technical verification, not just assumption.
Phase 6: Recover
Restore systems in prioritized order, starting with the most business-critical. Monitor closely for recurrence indicators — look for the same IOCs, not just new ones. Validate service integrity before giving the all-clear.
Phase 7: Communicate
Provide structured, timestamped updates by stakeholder type. Keep statements factual and avoid speculating about scope or attribution until you have evidence. Coordinate legal and privacy review before anything goes to external parties.
Phase 8: Learn
Run a post-incident review within a defined window — typically five to ten business days after closure while details are still fresh. Document root causes and control gaps honestly. Assign tracked remediation actions with named owners and realistic due dates.
6) Ransomware Readiness for Small Teams
Ransomware response is almost entirely determined by preparation. Speed of containment matters, but if your backups aren’t clean and your credential revocation process isn’t practiced, speed alone won’t save you.
Practical Readiness Controls
- Offline or immutable backup strategy for critical systems, stored separately from production networks
- Network segmentation between user endpoints and critical servers
- Documented and tested process for disabling privileged accounts quickly
- Known-good recovery images and rebuild playbooks ready before you need them
- Pre-established contact plan for legal counsel, your cyber insurer, and incident response partners
Ransomware Triage Priorities
- Stop the spread — isolate affected assets immediately, even if scope isn’t fully known yet
- Preserve evidence before any widespread rebuilding begins
- Confirm scope — what is encrypted, what data may have been exfiltrated, and what systems are still clean
- Protect backup and recovery infrastructure from being encrypted or deleted
- Align legal and communications response quickly, especially if customer or regulated data is involved
7) Contact Matrix Template
| Contact Type | Name/Role | Primary Channel | Backup Channel | Availability | Escalation Trigger |
|---|---|---|---|---|---|
| Incident Lead | 24/7 or business hours | Severity High or Critical | |||
| IT Operations | Host or service containment required | ||||
| Executive Sponsor | Business-impacting outage or data risk | ||||
| Legal/Privacy | Possible regulated data involvement | ||||
| Communications | Internal or external statement needed | ||||
| Cloud Provider/MSSP | Platform-level escalation required | ||||
| Backup/DR Vendor | Restore workflow initiated |
Keep this matrix current. Test contact reachability quarterly — don’t wait until an incident to discover a phone number has changed.
8) Severity Table for Small Teams
Simple levels with clear triggers work better than complex scoring under pressure. The goal is fast, consistent decisions, not precision.
| Severity | Typical Criteria | Required Response Time | Escalation |
|---|---|---|---|
| Low | Isolated suspicious activity with no confirmed impact | Same business day | IT owner informed |
| Medium | Confirmed compromise on limited asset scope | Within 4 hours | Incident lead and IT owner activated |
| High | Multi-system impact, credential abuse, or business disruption | Within 1 hour | Executive and legal/privacy notified |
| Critical | Widespread outage, likely data breach, or core business interruption | Immediately | Full incident team activation |
Severity Decision Guardrails
- When uncertain, default upward — especially if high-value systems are potentially affected
- Reclassify as new evidence arrives; don’t anchor to your initial assessment
- Document the reason for every severity change in the incident timeline
9) Tooling Stack for Small-Team IR
Tools support your process — they don’t replace it. A team with good process and basic tooling will outperform a team with enterprise tooling and no defined workflow.
| Tool / Platform | Practical IR Use |
|---|---|
| Wireshark | Packet-level triage and suspicious traffic analysis |
| Autopsy | Disk and artifact analysis for host forensics |
| Wazuh | Open-source endpoint and security event monitoring with SIEM capabilities |
| Splunk or ELK Stack | Centralized log correlation and incident timeline construction |
| Backup systems | Verified recovery and rollback operations |
| Ticketing platform | Action tracking, ownership assignment, and audit trail |
| Secure documentation workspace | Incident timeline, decisions, and evidence index management |
Tooling Principles
- Standardize formats for evidence entries and timeline notes from day one
- Prefer integrations that reduce manual copy-paste between systems — errors multiply under stress
- Maintain one source of truth for incident status so responders aren’t working from different versions
10) Common Mistakes That Hurt Small-Team Response
These mistakes come up repeatedly in incident post-mortems. Most of them are avoidable with a bit of upfront investment.
- Backups exist but restore procedures were never actually tested end-to-end
- No pre-approved communication templates, so messaging gets improvised and inconsistent
- Panic-driven containment actions taken without logging what was done or when
- Evidence overwritten or lost during rushed cleanup before scope was fully understood
- Decision authority unclear during high-severity events, causing delays or conflicting actions
- Incident closed without assigning corrective action ownership, so nothing actually changes
Practical Prevention Controls
- Run quarterly restore drills and document the outcome, including time to recovery
- Pre-approve stakeholder messaging templates so they’re ready when you need them
- Enforce timeline note-taking from the first alert — it takes seconds and saves hours later
- Gate cleanup actions behind an explicit evidence-preservation check
- Every post-incident action item must have a named owner before the incident is closed
11) 30-Day IR Readiness Plan for Lean Teams
Week 1: Build the Minimum Operating Kit
Assign roles and backups. Publish a severity matrix and a one-page response flow. Build the first version of your contact matrix.
Output: Version 1 IR playbook package
Week 2: Validate Telemetry and Evidence Process
Confirm logging coverage for critical assets. Test evidence storage and chain-of-custody template. Validate endpoint and network visibility paths.
Output: Telemetry and evidence readiness report
Week 3: Run a Scenario Tabletop and Fix Gaps
Simulate one ransomware-style and one credential abuse scenario. Measure time to role activation and escalation. Update the playbook with friction points discovered during the exercise.
Output: Tabletop findings and playbook revision log
Week 4: Execute Technical Drills and Leadership Reporting
Run a backup restore drill for a critical workload. Test emergency contact reachability. Deliver a readiness summary and next-quarter roadmap to leadership.
Output: Signed 30-day readiness status report
12) Practical Templates to Keep With the Playbook
Incident Timeline Template
| Time (UTC) | Event | Actor | System/Asset | Action Taken | Evidence Ref | Decision Owner |
|---|
Executive Update Template
| Section | Content Prompt |
|---|---|
| Current status | What is confirmed right now? |
| Business impact | Which services or users are affected? |
| Actions underway | What containment or recovery steps are currently active? |
| Next milestone | What decision or validation point is coming next? |
| Support needed | What approvals or resources are required from leadership? |
Post-Incident Action Tracker
| Action | Owner | Priority | Due Date | Status | Validation Method |
|---|
Small teams don’t need an enterprise-sized program to respond well. What they need is clarity, repetition, and ownership: a practical playbook, people who know their roles, tested recovery paths, and disciplined follow-through after every incident — including the minor ones.
IR Operations Worksheet for Small Teams
| Workstream | Owner | First Action | Validation Signal |
|---|---|---|---|
| Role clarity | Incident lead | Confirm primary and backup assignments for every role | Faster team activation during actual incidents |
| Evidence discipline | Technical responder | Standardize evidence log and chain-of-custody form | Better post-incident audit confidence |
| Communication flow | Comms owner | Pre-approve stakeholder update templates by audience | Reduced confusion and faster messaging during escalation |
| Recovery readiness | IT owner | Test restore path for the most critical business system | Measurable improvement in recovery time estimates |
Weekly Execution Checklist
- Verify contact matrix accuracy and confirm reachability for key contacts
- Check backup health and confirm restore test scheduling is on track
- Review open incident action items and ownership status
- Update severity thresholds or response procedures based on recent cases or near-misses
Case Handoff and Closure Package
| Artifact | Minimum Content | Consumer |
|---|---|---|
| Incident timeline | UTC-timestamped events, actors, decisions, and actions taken | Leadership and audit teams |
| Technical evidence pack | Logs, packet captures, and system artifacts with reference index | Security team and technical responders |
| Communication log | Internal and external messages with approval records | Legal, privacy, and communications teams |
| Corrective action tracker | Owner, due date, validation method for each action item | Operations and management |
Closure Quality Checks
- Were all critical decisions timestamped and attributed to a named decision owner?
- Did containment actions preserve enough evidence for root cause analysis?
- Are corrective actions assigned, scheduled, and tracked for follow-up validation?
90-Day Small-Team IR Hardening Cadence
Days 1–30
Finalize the one-page activation flow and role matrix. Run one tabletop on a credential abuse scenario. Validate evidence handling and storage workflow with a test exercise.
Days 31–60
Run restore and recovery drills for key business systems and document results. Improve communication templates with input from legal and comms. Start tracking mean time to acknowledge and mean time to contain as baseline metrics.
Days 61–90
Execute a second tabletop on a ransomware-style disruption scenario with a wider participant group. Audit corrective action completion from prior incidents and drills. Publish a quarterly IR readiness report with prioritized next steps.
| KPI | Why It Matters |
|---|---|
| Time to team activation | Shows operational readiness under pressure |
| Time to containment | Indicates how effectively the team limits blast radius |
| Recovery validation success rate | Measures business continuity reliability |
| Corrective action closure rate | Confirms the program is actually improving over time |
Small-team incident response becomes resilient when preparation, evidence handling, communication, and recovery testing are maintained as a continuous operating rhythm — not treated as a project that ends when the first playbook is written.
Readiness Drill Package — Small-Team Friendly
The single biggest improvement lever for a small team is repetition with lightweight documentation. Formal tabletops are valuable, but shorter, more frequent exercises build the muscle memory that matters when a real incident hits.
Monthly Tabletop (60 Minutes)
Pick one scenario — phishing leading to mailbox takeover, a ransomware alert, suspicious outbound traffic from a server. Walk through detection, triage, containment, communication, and recovery. Capture gaps as action items with owners and deadlines. Keep it practical, not theatrical.
Incident Communication Templates
| Template | Used For | Must Include |
|---|---|---|
| Initial notice | ”We are investigating” update | Confirmed impact, owners actively working it, time of next update |
| Containment notice | ”We have isolated or blocked” update | What changed operationally, residual risk, rollback notes |
| Closure summary | ”Resolved” update | Root cause summary, fixes implemented, open follow-up actions |
Post-Incident Review Checklist
- What detection signal worked and what signal was missed or delayed?
- Which access controls failed, were bypassed, or simply weren’t in place?
- Which step took longer than expected and why — permissions, tooling, communication gaps?
- What specific control, process, or training change would prevent recurrence?
Metrics That Keep You Honest
| Metric | Why It Matters |
|---|---|
| Time to acknowledge | Measures detection and triage responsiveness |
| Time to contain | Measures operational execution capability |
| Evidence completeness | Ensures decisions are traceable and defensible |
| Follow-up closure rate | Confirms that lessons learned actually result in changes |
A small-team IR playbook stays professional when it’s practiced regularly, communicated clearly, and improved through measurable actions after every exercise and real incident.
